AI-Powered NL-to-SQL System
TL;DR
LLM-powered backend system converting natural language to executable PostgreSQL queries using schema-aware prompting and a multi-layer validation pipeline. Built with Google Gemini, FastAPI, and asyncpg — includes fuzzy matching, SQL guardrails, cost-optimised on-demand LLM calls, query observability logging, and an interactive Streamlit UI with CSV export and schema exploration.
Project Overview
Most people who need data insights don't know SQL. They either wait for an analyst or go without the answer entirely. This project solves that problem directly. The AI-Powered NL-to-SQL System converts plain English questions into safe, optimised PostgreSQL queries and returns structured results — enabling non-technical users to query live databases without writing a single line of SQL.
Built with Google Gemini 2.5 Flash, FastAPI, and asyncpg, the system goes far beyond a simple prompt-to-query wrapper. It implements schema-aware context injection, a multi-layer validation pipeline, strict SQL safety guardrails, backend-controlled query execution, cost-optimised LLM usage, and a structured query observability system — patterns you would expect in a production AI backend.
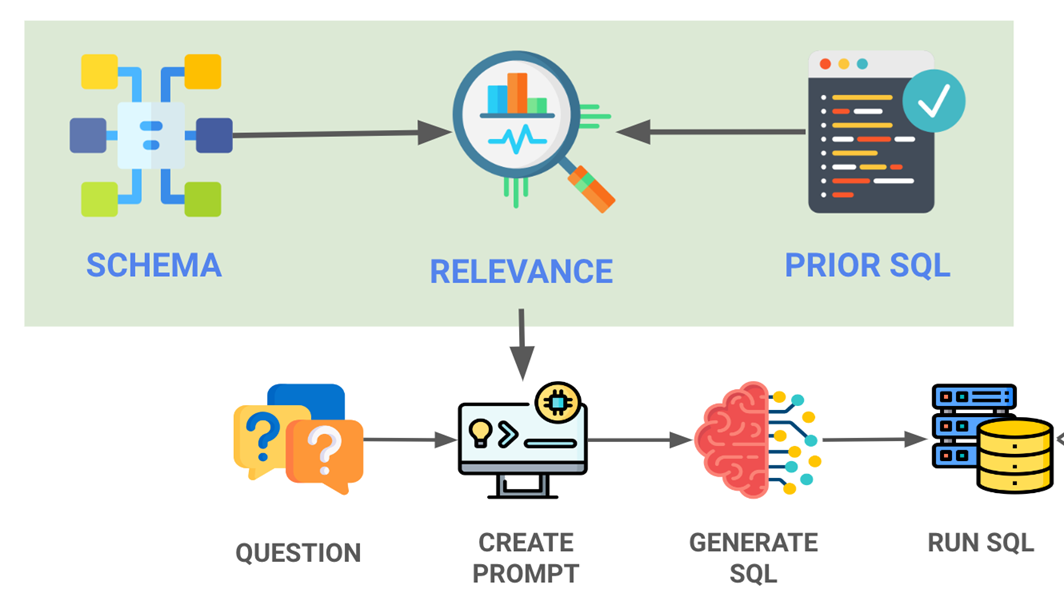
System Pipeline
Every query passes through a strict, ordered pipeline. No stage is skipped:
Key Features & Engineering Decisions
Schema-Aware Prompt Engineering:- Live database schema (tables, columns, PKs, FKs) is injected into every Gemini prompt from a fingerprinted, TTL-cached schema store.
- Prevents hallucinated table and column names — the model cannot generate SQL referencing schema that doesn't exist.
- Schema is MD5-fingerprinted and cached with a 1-hour TTL — cache refreshes only when the schema actually changes, not on every request.
- Layer 1 — Rule-Based Filter: Fast-reject via pattern matching for greetings, write-intent keywords, and clearly out-of-scope inputs. No LLM call consumed.
- Layer 2 — Fuzzy Schema Relevance:
difflib.SequenceMatcher(similarity threshold 0.75) maps user terms to schema keywords — handles typos like "produts" → "products" without rejection. - Layer 3 — LLM Intent Classifier: Only queries that pass layers 1 and 2 reach the LLM classifier, dramatically reducing token usage on invalid inputs.
- Strict allowlist — only
SELECTandWITH … SELECT(CTEs) are permitted. Any other statement pattern is rejected before execution. - Blocked keywords:
INSERT,UPDATE,DELETE,DROP,ALTER,TRUNCATE,EXECUTE,GRANT,REVOKE, and stacked statement separators. - SQL comment injection via
--and/* */explicitly blocked to prevent prompt injection via query strings. - Every query executes inside a
READ ONLYtransaction — a database-level second line of defence even if a statement slips through validation.
- LIMIT is never delegated to the LLM. The query executor injects row caps using a custom paren-depth parser that correctly identifies the outer
SELECTof CTEs — not the inner CTE body, which would break the query. - Prevents large full-table scans and protects system performance under all query patterns.
- Post-generation rule-based evaluator emits structured, machine-readable warnings surfaced in the API response and UI:
- On-demand explanation — plain-English SQL explanations are generated only when the user explicitly requests them via a separate
/explainendpoint. Zero unnecessary LLM calls during standard query execution. - Schema caching with fingerprint-based invalidation eliminates repeated database introspection calls.
- Two-stage validation (rules first, LLM second) means the majority of invalid inputs never reach a paid API call.
Modular Backend Architecture
| Service Layer | Module | Responsibility |
|---|---|---|
| GeminiProvider | llm/gemini_provider.py |
Async Gemini calls — exponential retry on 503s, automatic fallback model, truncation detection with doubled token-budget retry, SQL fence stripping |
| ClassifierService | services/classifier.py |
Fast-reject rules → fuzzy schema keyword match → LLM intent classification (3-layer defence) |
| NLToSQLService | services/nl_to_sql.py |
Schema-injected prompt building, SQL generation, session history injection for conversational follow-ups, on-demand explanation |
| ConfidenceEvaluator | services/confidence.py |
6 rule-based post-generation checks: missing filters, SELECT *, ambiguous columns, strict ILIKE, large result sets |
| SQLValidator | services/validator.py |
Allowlist-based safety gate — blocked keywords, SELECT-only enforcement, comment injection prevention |
| QueryExecutor | services/query_executor.py |
READ ONLY transaction, CTE-aware LIMIT injection via paren-depth parser, row capping, result serialisation |
| SchemaService | services/schema_service.py |
Schema extraction, 1-hour TTL cache, MD5 fingerprint change detection, manual and auto refresh |
Technical Implementation
Async API-Driven Backend (FastAPI):- Full async implementation using FastAPI and asyncpg — handles concurrent query requests without blocking.
- Clean endpoint design:
/query,/explain,/schema,/session/init,/session/history— each with a single clear responsibility. - Pydantic v2 schemas enforce strict input validation on all request payloads before any processing begins.
- CORS middleware configured to allow the standalone Streamlit frontend to call the API without a proxy.
- Each user session maintains isolated credentials and query history scoped by
session_id. - Last N turns of query history are injected into the SQL generation prompt, enabling natural follow-up questions ("now filter that by genre = Fiction") without restating the full context.
- Every query request is logged with full pipeline lifecycle data: user question, generated SQL, warnings, execution result, and error stage on failure.
- Logs stored in JSONL format (one record per query) including session ID, latency breakdown (LLM time, DB time, total), and status (success / failed / rejected).
- Logging runs as a non-blocking background task — zero impact on API response latency.
- Provides the foundation for analytics, performance monitoring, and prompt quality improvement over time.
- Natural language query interface with real-time SQL generation and result display.
- Schema explorer with progressive disclosure — tables shown first, columns expandable on demand, backed by the cached schema endpoint.
- CSV export of query results, enabling self-service analytics workflows for non-technical users.
- Confidence warnings and ambiguity flags surfaced inline in the UI so users understand result caveats without technical explanation.
- Demo mode — connects to a pre-seeded PostgreSQL library management database (books, members, borrowings). No credentials required.
- Custom mode — users provide their own PostgreSQL connection string and Gemini API key via
POST /session/init. Credentials are stored in-memory only, never persisted. Schema is auto-extracted and all prompts adapt automatically — making the system database-agnostic.
Video Preview
Key Learnings
- LLMs must be treated as unreliable infrastructure: 503 errors, model deprecations, and mid-output truncation are normal. Every Gemini call is wrapped with exponential retry, a fallback model, and truncation detection — the pipeline never crashes silently on an LLM failure.
- Backend owns all system-level constraints: LIMIT clauses, safety checks, and row caps live in backend code, not the LLM prompt. Delegating system constraints to the model is a reliability anti-pattern that breaks under real usage.
- Cost is a first-class design concern: Isolating explanation generation to an on-demand endpoint, using fast rule-based pre-filtering before LLM calls, and caching schema all reduce token usage significantly — and this discipline is what makes LLM systems scalable.
- CTEs require special handling for LIMIT injection: Naively appending LIMIT to a CTE truncates the inner query body, not the final result. A custom paren-depth parser was required to correctly target the outer SELECT — a PostgreSQL-specific edge case that can't be handled generically.
- Real users are messy: Typos, vague phrasing, and partial column names are the norm. The fuzzy matching layer using
difflibhandles these gracefully, reducing false rejections and making the system usable beyond controlled demos. - Modularity pays dividends immediately: Each service having one responsibility meant adding the confidence warning system, on-demand explain endpoint, and auto-LIMIT prompt rule each required touching exactly one file — not refactoring the entire codebase.
Future Work
- Add model drift detection using query log analytics — track SQL accuracy and warning frequency over time to identify prompt degradation as the underlying LLM is updated.
- Implement fine-tuning on domain-specific NL-SQL pairs for higher accuracy on specialised schemas (finance, healthcare) where generic prompting struggles with domain terminology.
- Evaluate streaming responses via FastAPI's
StreamingResponse— for large result sets, streaming rows as they are retrieved would significantly improve perceived latency.
Built by Om Patel — ML Engineer & Data Scientist.
Explore more projects on my
Portfolio.